1. Indexing
The indexing module is used to make pairs of records. These pairs are called candidate links or candidate matches. There are several indexing algorithms available such as blocking and sorted neighborhood indexing. See [christen2012] and [christen2008] for background information about indexation.
Christen, P. (2012). Data matching: concepts and techniques for record linkage, entity resolution, and duplicate detection. Springer Science & Business Media.
Christen, P. (2008). Febrl - A Freely Available Record Linkage System with a Graphical User Interface.
The indexing module can be used for both linking and duplicate detection. In case of duplicate detection, only pairs in the upper triangular part of the matrix are returned. This means that the first record in each record pair is the largest identifier. For example, (“A2”, “A1”), (5, 2) and (“acb”, “abc”). The following image shows the record pairs for a complete set of record pairs.
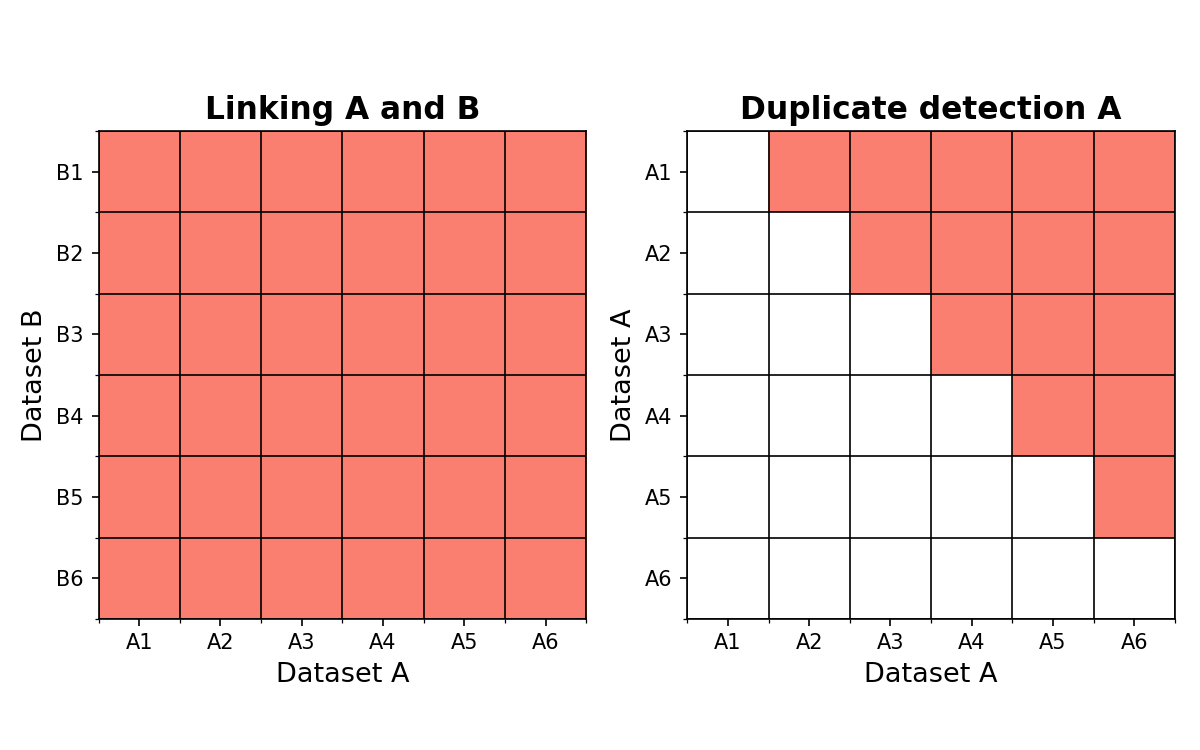
recordlinkage.Index object
- class recordlinkage.Index(algorithms=[])
Class to make an index of record pairs.
- Parameters:
algorithms (list) – A list of index algorithm classes. The classes are based on
recordlinkage.base.BaseIndexAlgorithm
Example
Consider two historical datasets with census data to link. The datasets are named
census_data_1980andcensus_data_1990:indexer = recordlinkage.Index() indexer.block(left_on='first_name', right_on='givenname') indexer.index(census_data_1980, census_data_1990)
- add(model)
Add a index method.
This method is used to add index algorithms. If multiple algorithms are added, the union of the record pairs from the algorithm is taken.
- Parameters:
model (list, class) – A (list of) index algorithm(s) from
recordlinkage.index.
- index(x, x_link=None)
Make an index of record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
- full()
Add a ‘full’ index.
Shortcut of
recordlinkage.index.Full:from recordlinkage.index import Full indexer = recordlinkage.Index() indexer.add(Full())
- block(*args, **kwargs)
Add a block index.
Shortcut of
recordlinkage.index.Block:from recordlinkage.index import Block indexer = recordlinkage.Index() indexer.add(Block())
- sortedneighbourhood(*args, **kwargs)
Add a Sorted Neighbourhood Index.
Shortcut of
recordlinkage.index.SortedNeighbourhood:from recordlinkage.index import SortedNeighbourhood indexer = recordlinkage.Index() indexer.add(SortedNeighbourhood())
- random(*args, **kwargs)
Add a random index.
Shortcut of
recordlinkage.index.Random:from recordlinkage.index import Random indexer = recordlinkage.Index() indexer.add(Random())
Algorithms
The Python Record Linkage Toolkit contains basic and advanced indexing (or blocking) algorithms to make record pairs. The algorithms are Python classes. Popular algorithms in the toolkit are:
The algorithms are available in the submodule recordlinkage.index. Import the algorithms in the following way (use blocking algorithm as example):
from recordlinkage.index import Block
The full reference for the indexing algorithms in the toolkit is given below.
- class recordlinkage.index.Full(**kwargs)
Class to generate a ‘full’ index.
A full index is an index with all possible combinations of record pairs. In case of linking, this indexation method generates the cartesian product of both DataFrame’s. In case of deduplicating DataFrame A, this indexation method are the pairs defined by the upper triangular matrix of the A x A.
- Parameters:
**kwargs – Additional keyword arguments to pass to
recordlinkage.base.BaseIndexAlgorithm.
Note
This indexation method can be slow for large DataFrame’s. The number of comparisons scales quadratic. Also, not all classifiers work well with large numbers of record pairs were most of the pairs are distinct.
- index(x, x_link=None)
Make an index of record pairs.
Use a custom function to make record pairs of one or two dataframes. Each function should return a pandas.MultiIndex with record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
- class recordlinkage.index.Block(left_on=None, right_on=None, **kwargs)
Make candidate record pairs that agree on one or more variables.
Returns all record pairs that agree on the given variable(s). This method is known as blocking. Blocking is an effective way to make a subset of the record space (A * B).
- Parameters:
left_on (label, optional) – A column name or a list of column names of dataframe A. These columns are used to block on.
right_on (label, optional) – A column name or a list of column names of dataframe B. These columns are used to block on. If ‘right_on’ is None, the left_on value is used. Default None.
**kwargs – Additional keyword arguments to pass to
recordlinkage.base.BaseIndexAlgorithm.
Examples
In the following example, the record pairs are made for two historical datasets with census data. The datasets are named
census_data_1980andcensus_data_1990.>>> indexer = recordlinkage.BlockIndex(on='first_name') >>> indexer.index(census_data_1980, census_data_1990)
- index(x, x_link=None)
Make an index of record pairs.
Use a custom function to make record pairs of one or two dataframes. Each function should return a pandas.MultiIndex with record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
- class recordlinkage.index.SortedNeighbourhood(left_on=None, right_on=None, window=3, sorting_key_values=None, block_on=[], block_left_on=[], block_right_on=[], **kwargs)
Make candidate record pairs with the SortedNeighbourhood algorithm.
This algorithm returns record pairs that agree on the sorting key, but also records pairs in their neighbourhood. A large window size results in more record pairs. A window size of 1 returns the blocking index.
The Sorted Neighbourhood Index method is a great method when there is relatively large amount of spelling mistakes. Blocking will fail in that situation because it excludes to many records on minor spelling mistakes.
- Parameters:
left_on (label, optional) – The column name of the sorting key of the first/left dataframe.
right_on (label, optional) – The column name of the sorting key of the second/right dataframe.
window (int, optional) – The width of the window, default is 3
sorting_key_values (array, optional) – A list of sorting key values (optional).
block_on (label) – Additional columns to apply standard blocking on.
block_left_on (label) – Additional columns in the left dataframe to apply standard blocking on.
block_right_on (label) – Additional columns in the right dataframe to apply standard blocking on.
**kwargs – Additional keyword arguments to pass to
recordlinkage.base.BaseIndexAlgorithm.
Examples
In the following example, the record pairs are made for two historical datasets with census data. The datasets are named
census_data_1980andcensus_data_1990.>>> indexer = recordlinkage.SortedNeighbourhoodIndex( 'first_name', window=9 ) >>> indexer.index(census_data_1980, census_data_1990)
When the sorting key has different names in both dataframes:
>>> indexer = recordlinkage.SortedNeighbourhoodIndex( left_on='first_name', right_on='given_name', window=9 ) >>> indexer.index(census_data_1980, census_data_1990)
- index(x, x_link=None)
Make an index of record pairs.
Use a custom function to make record pairs of one or two dataframes. Each function should return a pandas.MultiIndex with record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
- class recordlinkage.index.Random(n, replace=True, random_state=None, **kwargs)
Class to generate random pairs of records.
This class returns random pairs of records with or without replacement. Use the random_state parameter to seed the algorithm and reproduce results. This way to make record pairs is useful for the training of unsupervised learning models for record linkage.
- Parameters:
n (int) – The number of record pairs to return. In case replace=False, the integer n should be bounded by 0 < n <= n_max where n_max is the maximum number of pairs possible.
replace (bool, optional) – Whether the sample of record pairs is with or without replacement. Default: True
random_state (int or numpy.random.RandomState, optional) – Seed for the random number generator (if int), or numpy.RandomState object.
**kwargs – Additional keyword arguments to pass to
recordlinkage.base.BaseIndexAlgorithm.
- index(x, x_link=None)
Make an index of record pairs.
Use a custom function to make record pairs of one or two dataframes. Each function should return a pandas.MultiIndex with record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
User-defined algorithms
A user-defined algorithm can be defined based on
recordlinkage.base.BaseIndexAlgorithm. The recordlinkage.base.BaseIndexAlgorithm class is an abstract base
class that is used for indexing algorithms. The classes
are inherited from this abstract base class. You can use BaseIndexAlgorithm to create a user-defined/custom algorithm.
To create a custom algorithm, subclass the
recordlinkage.base.BaseIndexAlgorithm. In the subclass, overwrite the
recordlinkage.base.BaseIndexAlgorithm._link_index() method in case of
linking two datasets. This method accepts two (tuples of)
pandas.Series objects as arguments. Based on these Series objects,
you create record pairs. The record pairs need to be returned in a 2-level
pandas.MultiIndex object. The pandas.MultiIndex.names are the
name of index of DataFrame A and name of the index of DataFrame B
respectively. Overwrite the
recordlinkage.base.BaseIndexAlgorithm._dedup_index() method in case of
finding link within a single dataset (deduplication). This method accepts a
single (tuples of) pandas.Series objects as arguments.
The algorithm for linking data frames can be used for finding duplicates as well. In this situation, DataFrame B is a copy of DataFrame A. The Pairs class removes pairs like (record_i, record_i) and one of the following (record_i, record_j) (record_j, record_i) under the hood. As result of this, only unique combinations are returned. If you do have a specific algorithm for finding duplicates, then you can overwrite the _dedup_index method. This method accepts only one argument (DataFrame A) and the internal base class does not look for combinations like explained above.
- class recordlinkage.base.BaseIndexAlgorithm(verify_integrity=True, suffixes=('_1', '_2'))
Base class for all index algorithms.
BaseIndexAlgorithm is an abstract class for indexing algorithms. The method
_link_index()- Parameters:
Example
Make your own indexation class:
class CustomIndex(BaseIndexAlgorithm): def _link_index(self, df_a, df_b): # Custom index for linking. return ... def _dedup_index(self, df_a): # Custom index for duplicate detection, optional. return ...
Call the class in the same way:
custom_index = CustomIndex(): custom_index.index()
- _link_index(df_a, df_b)
Build an index for linking two datasets.
- Parameters:
df_a ((tuple of) pandas.Series) – The data of the left DataFrame to build the index with.
df_b ((tuple of) pandas.Series) – The data of the right DataFrame to build the index with.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index values of two records.
- _dedup_index(df_a)
Build an index for duplicate detection in a dataset.
This method can be used to implement an algorithm for duplicate detection. This method is optional if method
_link_index()is implemented.- Parameters:
df_a ((tuple of) pandas.Series) – The data of the DataFrame to build the index with.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index values of two records. The records are sampled from the lower triangular part of the matrix.
- index(x, x_link=None)
Make an index of record pairs.
Use a custom function to make record pairs of one or two dataframes. Each function should return a pandas.MultiIndex with record pairs.
- Parameters:
x (pandas.DataFrame) – A pandas DataFrame. When x_link is None, the algorithm makes record pairs within the DataFrame. When x_link is not empty, the algorithm makes pairs between x and x_link.
x_link (pandas.DataFrame, optional) – A second DataFrame to link with the DataFrame x.
- Returns:
pandas.MultiIndex – A pandas.MultiIndex with record pairs. Each record pair contains the index labels of two records.
Examples
import recordlinkage as rl
from recordlinkage.datasets import load_febrl4
from recordlinkage.index import Block
df_a, df_b = load_febrl4()
indexer = rl.Index()
indexer.add(Block('given_name', 'given_name'))
indexer.add(Block('surname', 'surname'))
indexer.index(df_a, df_b)
Equivalent code:
import recordlinkage as rl
from recordlinkage.datasets import load_febrl4
df_a, df_b = load_febrl4()
indexer = rl.Index()
indexer.block('given_name', 'given_name')
indexer.block('surname', 'surname')
index.index(df_a, df_b)
This example shows how to implement a custom indexing algorithm. The algorithm returns all record pairs of which the given names starts with the letter ‘W’.
import recordlinkage
from recordlinkage.datasets import load_febrl4
df_a, df_b = load_febrl4()
from recordlinkage.base import BaseIndexAlgorithm
class FirstLetterWIndex(BaseIndexAlgorithm):
"""Custom class for indexing"""
def _link_index(self, df_a, df_b):
"""Make pairs with given names starting with the letter 'w'."""
# Select records with names starting with a w.
name_a_w = df_a[df_a['given_name'].str.startswith('w') == True]
name_b_w = df_b[df_b['given_name'].str.startswith('w') == True]
# Make a product of the two numpy arrays
return pandas.MultiIndex.from_product(
[name_a_w.index.values, name_b_w.index.values],
names=[df_a.index.name, df_b.index.name]
)
indexer = FirstLetterWIndex()
candidate_pairs = indexer.index(df_a, df_b)
print ('Returns a', type(candidate_pairs).__name__)
print ('Number of candidate record pairs starting with the letter w:', len(candidate_pairs))
The custom index class below does not restrict the first letter to ‘w’, but the first letter is an argument (named letter). This letter can is initialized during the setup of the class.
class FirstLetterIndex(BaseIndexAlgorithm):
"""Custom class for indexing"""
def __init__(self, letter):
super(FirstLetterIndex, self).__init__()
# the letter to save
self.letter = letter
def _link_index(self, df_a, df_b):
"""Make record pairs that agree on the first letter of the given name."""
# Select records with names starting with a 'letter'.
a_startswith_w = df_a[df_a['given_name'].str.startswith(self.letter) == True]
b_startswith_w = df_b[df_b['given_name'].str.startswith(self.letter) == True]
# Make a product of the two numpy arrays
return pandas.MultiIndex.from_product(
[a_startswith_w.index.values, b_startswith_w.index.values],
names=[df_a.index.name, df_b.index.name]
)